GAN(Generative Adversaril Network)
비지도 학습의 대표적인 선두주자, GAN

Written by Jung Eun
11 minute read
intro
지도학습과 비지도학습의 궁극적인 목표 중 하나는 데이터를 기반으로 미래를 예측하는 것이다. 하지만 지도학습은 정답이 주어진 데이터만을 사용할 수 있기 때문에 사용할 수 있기 때문에 사용할 수 있는 데이터 양의 한계가 있다. 따라서 대부분의 인공지능 전문가들은 미래의 인공지능 기술은 지도학습이 아닌, 비지도학습이 선도하게 될 것이라고 전망한다. 이러한 비지도학습의 대표적인 선두주자로 Generative Adversarial Network(GAN)이 있다.
GAN
비지도학습 GAN은 원 데이터가 가지고 있는 확률 분포를 추정 인공신경망이 그 분포를 만들어 낼 수 있도록 한다는 점에서 단순한 군집화 기반의 비지도학습과 차이가 있다.
- G - Ganerative
- A - Adbersarial
- N - Network
GAN은 ‘생상적 적대적 신경망의 약자로, 생성자와 식별자가 서로 경쟁(Adversarial)하며 데이터를 생성하는 모델을 의미한다. 그리고 GAN은 ‘비지도학습’ 이다.
GAN을 이해하기 위해서는 먼저 확률 분포의 개념을 알아야한다.
📌확률분포
- 확률분포
- 확률 변수가 특정한 값을 가질 확률을 나타내는 함수
- GAN에서 다루고자 하는 모든 데이터는 확률 분포를 가진 랜덤변수(
Random Variable) - 랜덤변수는 측정할 때마다 다른 값이 나옴, 하지만 특정한 확률분포를 따르는 숫자를 생성
- 랜덤변수에 대한 확률 분포를 알면 랜덤변수(데이터)에 대한 전부를 이해할 수 있음
- 궁극적인 목적
- 데이터의 통계적 특성 분석: 확률 분포를 알면 그 데이터의 예측 기댓값, 데이터의 분산을 알아낼 수 있음
- 원 데이터와 유사한 값을 가진 데이터 생성: 주어진 확률 분포를 따르도록 데이터를 임의 생성하면 그 데이터는 확률분포를 구할 때 사용한 데이터와 유사한 값을 가짐
- GAN과 같은 비지도학습이 머신러닝 알고리즘으로 데이터에 대한 확률분포를 모델링 할 수 있으면, 원데이터와 확률분포가 정확히 공유하는 무한한 많은 새로운 데이터를 새로 생성할 수 있음
📌GAN의 개념
GAN은 판별자 D와 생성자 G로 구성되어 있다.
- 판별자 D: 분류를 담당하는 모델, 2014년 NIPS에서 lan Goodfellow가 발표한 회귀생성 모델
- 생성자 G: 회귀생성을 담당하는 모델
GAN은 판별자 D와 생성자 G가 서로의 성능을 개선해 적대적으로 경쟁해가는 모델이다.
EX)
쉽게 말해 경찰과 지폐 위조범의 대립과 같은 방식이다.
- 지폐 위조점(생성자 G)은 경찰(분류자 D)을 최대한 열심히 속이려고 하고,
- 경찰은 위조된 지폐와 진짜 지폐를 두고 분류하기 위해 노력한다.
- 이러한 경쟁이 지속적으로 학습되면 결과적으로 진짜 지폐와 위조지폐를 구별할 수 없을 정도의 상태가 되며, 진짜와 거의 차이가 없는 가짜 지페를 만들 수 있다.
- 수학적으로 생성자 G는 앞에서 말한 원 데이터의 확률 분포를 알아내려고 노력하며, 학습이 종료된 후에는 원 데이터의 확률분포를 따른 새로운 데이터를 만들어 내게 됩니다.
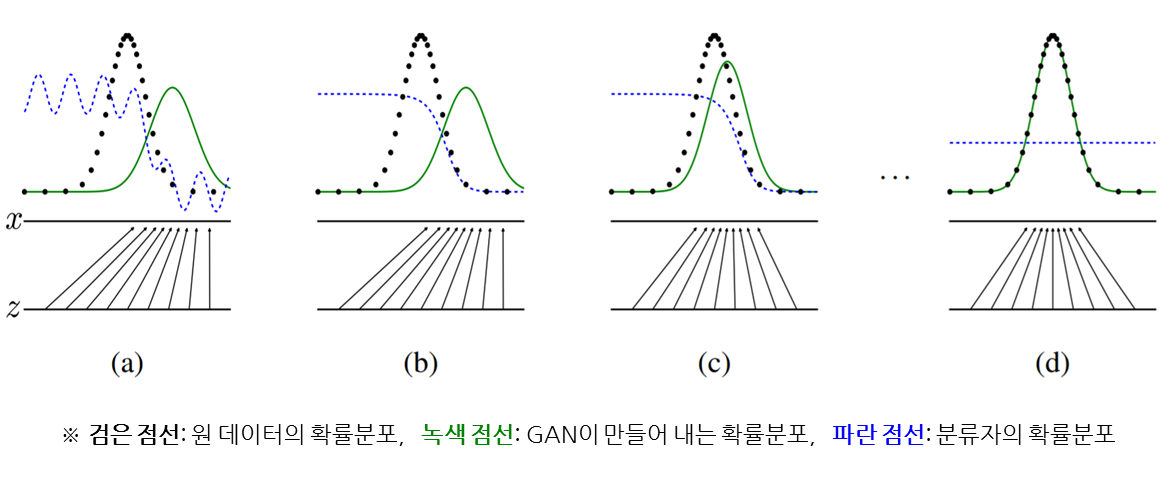
[GAN에서 학습을 통해 확률분포를 맞추어 나가는 과정 - Ian.J.Goodfellow의 'Generative Adversarial Networks' 논문 인용]
위 그래프에서 원 데이터의 확률분포에 대한 학습이 거듭 진행됨에 따라 GAN이 만들어내는 확률 분포가 거의 동일해지는 것을 확인할 수 있다. 이렇게 되면 파란색 점섬(분류자 D)는 더 이상 분류를 해도 의미가 없는 0.5라는 확률 값을 뱉어내게 된다. 이것은 동전을 던져 앞면과 뒷면을 맞추는 확률이 0.5인 것처럼 GAN에 의한 만들어진 데이터가 진짜인지 가짜인지 맞출 확률이 0.5가 되면서 분류자가 의미 없게 되는 것이다.

여기서 경찰은 분류 모델, 위조지폐범은 생성모델을 의미하며, GAN은 최대한 진짜 같은 데이터를 생성하려는 생성모델과 진짜와 가짜를 판별하려는 분류 모델이 각각 존재하여 서로 적대적 학습합니다.
GAN의 구조와 원리
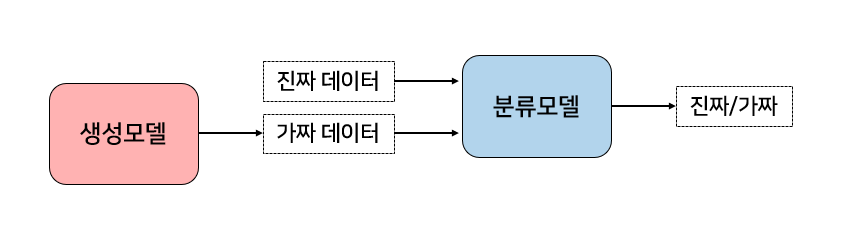
- 생성모델(Generator): 생성된 데이터를 받아 실제 데이터와 비슷한 데이터를 만들어내도록 학습
- 분류모델(Discriminator): 실제 데이터와 생성자가 생성한 가짜 데이터를 구별하도록 학습
적대적 학습에서 분류 모델을 먼저 학습시킨 후, 생성 모델을 학습시키는 과정에서 서로 주고 받으면서 반복 진행한다.
📌분류 모델의 학습
- 진짜 데이터를 입력해서 네트워크가 해당 데이터를 진짜로 분류하도록 학습
- 첫번째와 반대로 생성 모델에서 생성한 가짜 데이터를 입력해서 해당 데이터를 가짜로 분류하도록 학습
- 위 과정을 통해 분류 모델은 진짜 데이터를 진짜로, 가자 데이터를 가짜로 분류할 수 있게 된다.
분류 모델을 학습시킨 다음에 학습된 분류 모델을 속이는 방향으로 생성 모델을 학습시켜야한다.
📌생성 모델의 학습
- 생성 모델에서 만들어낸 가짜 데이터를 분류 모델에 입력
- 가짜 데이터를 진짜라고 분류할 만큼 진짜 데이터와 유사한 데이터를 만들어 내도록 생성 모델을 학습
- 이와 같은 학습과정을 반복하면 분류 모델과 생성 모델이 서로 적대적인 경쟁자로 인식하여 모두 발전하게 된다.
결과적으로, 생성 모델은 진짜 데이터와 완벽히 유사한 가짜 데이터를 만들 수 있게 되고 이에 따라 분류 모델은 진짜 데이터와 가짜 데이터를 구분할 수 없게 된다. 즉, GAN은 생성 모델은 분류에 성공할 확률을 낮추려 하고, 분류 모델은 분류에 성공할 확률을 높이려 하면서 서로가 서로를 경쟁적으로 발전시키는 구조를 이루고 있다.
📌GAN의 손실함수 - Minmax Problem
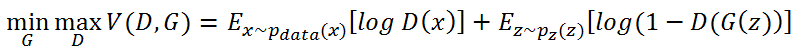
[첫번째 항] x~pdata(x)
- 실제 데이터(x)에 대한 확률분포에서 샘플링한 데이터
[두번째 항] z~pz(z)
- 일반적으로 가우시안분포를 사용하는 임의의 노이즈에서 샘플링한 데이터
- z = latent vector, 차원이 줄어든 채로 데이터를 잘 설명할 수 있는 잠재 공간에서의 벡터
위 수식 속,
- D(x)는 분류자이고 진짜 확률을 의미하는 0과 1 사이의 값이다.
- 데이터가 진짜면 D(x)는 1, 가짜면 0의 값이 나온다.
- 두번째 항에 있는 D(G(z))는 G가 만들어낸 데이터인 G(z)가 진짜라고 판단되면 1, 가짜라고 판단되면 0의 값을 가진다
우선 D가 V(D,G)를 최대화하는 관점에서 생각해보자. 위 수식을 최대화하기 위해서는
- 우변의 첫번째 항과 두번째 항이 모두 최대가 되어야 하므로 log D(x) 와 log(1-D(G(z)) 모두 최대가 되어야한다.
- D(x)는 1이 되어야 하며, 이는 실제 데이터를 진짜라고 분류하도록 D를 학습하는 것
- 1-D(G(z))도 1이 되어 D(G(z))는 따라서 0이 되어야하며, 이는 생성자가 만들어낸 가짜 데이터를 가짜라고 분류하도록 분류자를 학습하는 것
즉, V(D,G)가 최대화하는 방향으로 분류자 D를 학습하고 V(D, G)를 최소화하는 방향으로 생성자를 학습하는 것을 Minmax Problem이라고 한다.
이때, 생성 모델로서의 GAN이 데이터를 우연히 만들어 내는 것인지, 데이터를 완벽히 이해하고 있는 가치 있는 모델인지 알아보는 것이 중요하다.
이를 위해 생성자로서 메커니즘을 자세히 살펴봐야한다.
📌생성자로서 메커니즘
- latent vector z는 생성자 G이 입력으로 사용
- G의 출력 = 사람의 얼굴
- 왼쪽을 바라보는 얼굴을 만들어내는 z(왼쪽)들의 평균 벡터와 오른쪽을 보고 있는 얼굴 대응하는 z(오른쪽)들의 평균을 계산
- 이 두 벡터 사이의 축을 중간에서 보간(interpolation)하여 생성자로 입력
- 아래그림처럼 천천히 회전하는 얼굴이 나오는 것을 확인할 수 있음
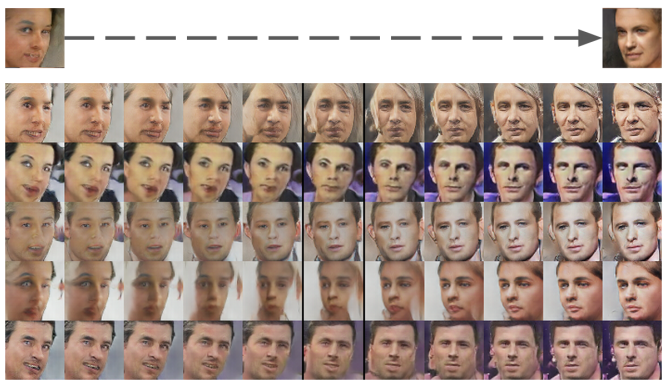
이 결과 생성자는 학습한 딥러닝 매핑 (z → G(z))이 단순히 불연속적인 1:1 매칭이 아니라, 정확히 영상의 의미를 이해하고 영상이라는 데이터의 확률분포를 정확히 표현하고 있어서, 입력에서의 약간의 변화가 출력에서도 부드러운 변화로 표현가능하다는 놀라운 사실을 보여준다.
이러한 GAN의 놀라운 개념을 증명시켜주는 유명한 사례에는 이미지의 산술적인 연산이 있다. ‘안경을 쓴 남자’ 이미지를 생성하는 z에서 ‘안경을 쓰지 않은 남자’ 이미지의 입력인 z를 빼고 ‘안경을 쓰지 않은 여자’ 이미지에 해당하는 z를 생성자 G에 넣어주면 ‘안경을 쓴 여자’ 이미지가 아래 그림처럼 생성된다는 것을 밝혀냈다.
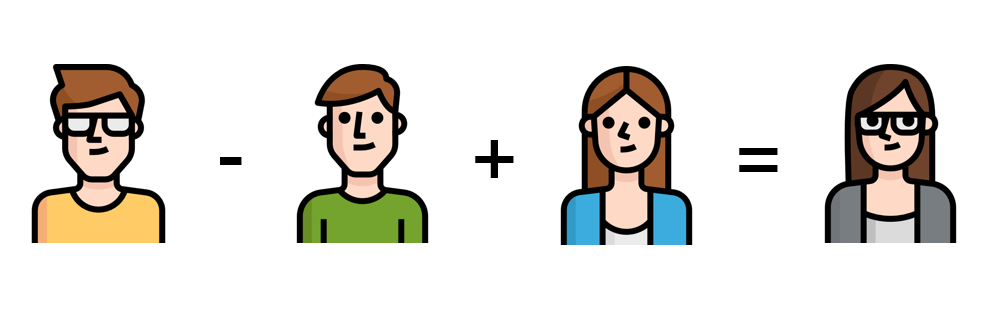
이는 GAN의 생성자의 결과물이 우리가 원하는 데로 마음껏 조작할 수 있다는 가능성을 확인한 것이며, 단순한 데이터의 분류로서의 이해가 아닌 새로운 것을 창조할 능력을 가지게 된 것이다.
GAN의 활용 사례와 발전방향
📌GAN의 한계점
lan Goodfellow가 제안한 GAN은 근본적으로 3가지 정도의 한계를 가지고 있다.
- 기존 GAN만으로는 훈련 성능이 그다지 좋지 않다.
- 생성자와 분류자가 대결하며 학습하는 구도인 만큼 학습이 불안정함
- 생성자와 분류자가 서로 균형있게 훈련을 주고 받아야하는데, 두 모델 간 실력차가 발생하는 경우 훈련이 한쪽에 치우쳐 궁긍적 성능 제약
- 사용된 생성자의 결과물 형태가 어떠한 연유와 과정을 통해 나왔는지 알 수 없다.
- 새롭게 만들어진 데이터가 얼마나 정확한지 객관적으로 판단하기 어렵다.
위 한계점 중 첫 번째 한계를 극복하기 위해 GAN의 훈련 성능을 높이기 위한 다양한 연구가 진행되고 있다.
대표적인 것이 DCGAN(Deep Convolutional GAN)이다.
📌DCGAN
- DCGAN: GAN에 지도학습에서 이미 폭넓게 적용되던 CNN을 사용한 것
- 비지도학습 적용을 위해 기존의 fully connected DNN 대신 CNN(Convolutional Neural Netwrok) 기법으로 신경망을 구성
- CNN: 전체 데이터의 특정 부분에 대한 주요 특징 값을 추출하는 Convolutional layer(필터 역할)와 추출한 특징 중 제일 중요한 값만 추려내는 Pooling layer가 교차하면서 이루어짐
- 이때 이미지와 같은 부분의 특징을 읽어내는 성능이 탁월하여 학습이 잘 된다는 장점을 GAN의 이미지 생성에 적용
- 각 층 해당 뉴런의 입력 대비 출력을 얼마나 반영할지 결정하는 함수인 활성화 함수(Activation function)의 적절한 선택이 중요
- GAN을 위해 leaky_ReLU 함수를 사용하여 분류자의 학습 효율 높임
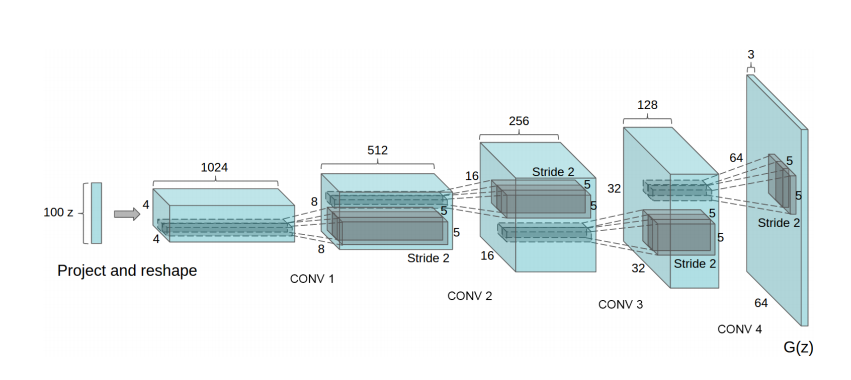
DCGAN의 생성자 구조도(100차원 latent vector z가 64*64 픽셀의 이미지를 생성)
이러한 구조를 통해 DCGAN은 GAN의 학습에 대한 문제점을 상당 부분 극복해내면서 주목을 받았다.
DCGAN의 등장으로 성능이 향상된 GAN을 통해 더 완벽한 가짜 데이터를 만들어내는 모델이 속속 연구됨에 따라 GAN의 활용 범위 역시 더욱 넓어지고 있다. 특히, 2017년 워싱턴대학교 연구팀은 영상 합성에 GAN을 적용하여 만든 ‘오바바 전 미국 대톡령의 가짜 영상’을 공개해 화제가 됐다. 그들은 오바마 대통령의 실제 연설에서 음성을 추출한 후, 음성에 맞게 입 모양을 생성하도로고 GAN을 학습하여 가짜 영상을 만들었다. 진짜처럼 보이는 아래 사진들은 모두 GAN을 이용해 만들어낸 가짜 영상의 일부분이다.

GAN을 통해 합성한 오바마 전 미국 대통령의 연설 영상
즉, latent vector의 산술적 연산을 통해 ‘안경을 새로 씌울 수 있는’ GAN의 근본적인 개념과 마찬가지로, 오바마의 얼굴을 만들어낸 latent vector에서 입술에 해당하는 부분만 벡터 연산을 통해 산술적으로 대체해주면 얼마든지 창조적으로 얼굴을 조작할 수 있다.
📌Real-eye-opener
이러한 GAN의 뛰어난 능력을 이용한 대표적인 사례로 페이스백에서 개발한 Real-eye-opene이 있다. 사진을 찍는 순산 실수로 눈을 감아 사진을 망친 경험이 있는 사람이면 누구나 공감할 만한 기술이다.
- Real-eye-opener: 눈을 감은 사진에 가짜 눈을 생성해 눈을 뜨고 있는 사진으로 만들어주는 기술
- GAN을 통해 얼굴에 눈을 합성
- 오바바 전 대통령의 연설 영상에 합성한 것과 마찬가지로, 원하는 눈 모양을 latent vector에 반영하여 눈 모양이 대체된 새로운 얼굴 전체에 생성

위 사진에서 (a)/(b)는 각각 사람이 눈을 뜨고/감고 있는 실제 사진이며, 목표는 (b)의 사진에 (a)의 논 모양을 합성하는 것이다. (c)는 단순히 포토샵을 이용해 (b)에 (a)의 눈을 합성한 결과이며, (d)는 GAN을 이용해 합성한 결과이다. (c)는 합성한 눈과 얼굴 사이의 경계가 부자연스러운데 비해 (d)는 훨씬 자연스럽고 실제 사람의 사진과 유사하다.
📌Image translation
- Image translation: 우리가 원하는대로 이미지를 바꾸어 재성성하는 것
- 흑백사진을 컬러 사진으로, 간단한 일러스트를 구체적인 사진으로 만들어내는 등

cycleGAN을 통한 Image Translation
위 사진은 2017년 UC 버클리에서 GAN을 Image translation에 적용하기 위해 GAN 구조에 원래 이미지의 형태를 잘 유지할 수 있는 조건을 추가한 cycleGAN 모델의 결과이다.
- 사진 -> 모네 화풍의 그림
- 모네의 그림 -> 사진
- 얼룩말 사진 -> 말
- 여름 분위기 사진 -> 겨울 분위기 사진
최근 GAN은 음성신호 및 자연어 처리 등으로 영역이 확대되어 다양한 분야에 적용되며 빠르게 발전하고 있어 가장 유망한 인공신경망 알고리즘으로 곽광받는 중이다. 하지만 가장 기본적인 해결과제인 학습 안정화가 남아있다. DCGAN을 통해 어느 정도 안정된 학습을 진행할 수 있게 됐지만, 더 다양한 분야에 활용하고 정밀한 성능을 얻기 위해서는 향상된 신경망 구조 개발 등의 후속 연구가 필요해보인다. 그 외에도 GAN은 지도학습 모델을 추가 적용하여 성능을 높이고, 강화 학습 및 또 다른 비지도학습 알고리즘과 결합하는 방향으로 계속해서 발전해 나갈 것이다.
References
[새로운 인공지능 기술 GAN] ① 스스로 학습하는 인공지능
[새로운 인공지능 기술 GAN] ② GAN의 개념과 이해
[새로운 인공지능 기술 GAN] ③ GAN의 활용 사례와 발전방향
